SATIS 2018
SATIS 2018 — Day 1
 |
| Sommarøy. |
 |
Then, he explained why is “good” to become a SIGOPS member…
 |
… and passed the mic to the first speaker: Dag Johansen.
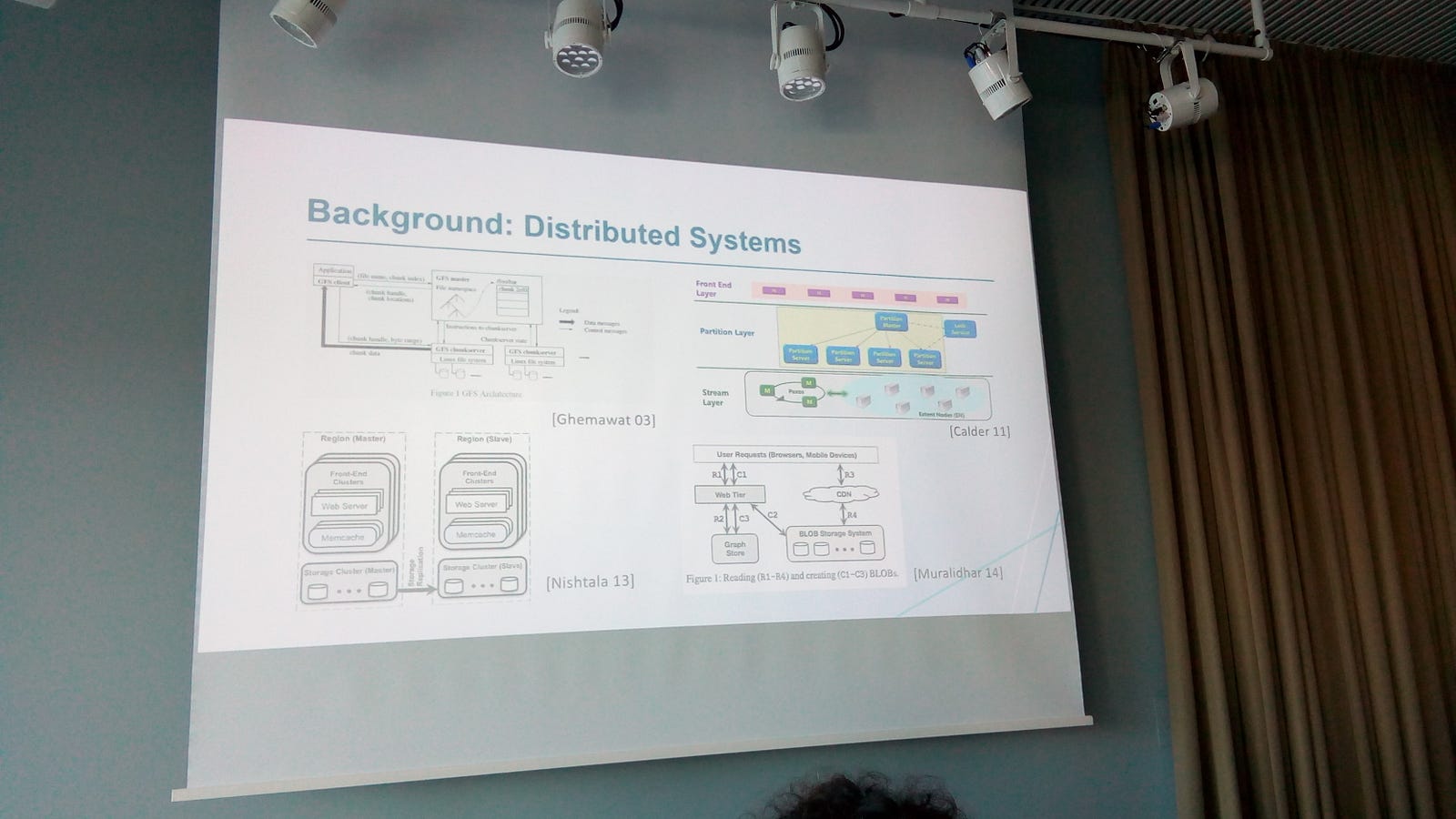
Johansen’s talk started with a brief introduction to distributed systems, in order to put the audience in the context, and showing the similar characteristics of all distributed systems, that is, the 3-layer division of: User Interface (UI), Processing, and Data Storage.
 |
Why soccer analytics? it is a very good scenario to test the distributed systems paradox: a system that must be simple (UI) but complex (behind the scenes). Quoting Johansen:
“When people turn on a switch they don’t care how the electricity got there”
But why a distributed system? what is the problem with centralized? we distribute to gain responsiveness. In this use case: football (soccer):
- 90+ minutes indeterministic flow of game
- Individual athletes, collective team
- Non-predictable outcome (few foals: 1–0 & 1–1 final scores [anderson 13])
Problem: How to accurately measure all the training modalities imposed on the athlete.
Related work: Manually counting (steps, distance, reps, etc), GPS and accelerometers, Video motion analysis
Approach: Develop scalable, non-invasive, highly available, precise sports system, monitoring external load, enabling visual feedback and personalized intervention in real time
Match and Training Toolkit:
- Capture positional data
- Capture video: analytics (semi-automatic feature extraction), visual feedback (complete field; zoom), precision introduced delay
- Non-functional properties: scalable, available, non-invasive, precise (capture correct details), real-time
Proof of concept: 23 people recording a match on video, OpenCV analysis got < 1 fps, and you need 33 fps for real-time. Then, distributed systems came to the rescue.
 |
 |
After Dag’s talk, Leslie Lamport gave two talks, in the first entitled “Algorithms are not programs” he defended the idea that algorithms shuld be described and written with math rather than programming languages or pseudo-languages. This applies to many more algorithms than the ones taught in algorithm courses. Citing Lamport:
“You don’t produce 10x less code by better coding. You do it with a better algorithm, which come from mathematical thinking”.
The second talk was Lamport’s Turing Award talk entitled: “The early days of concurrency: a memoir”. In the talk, Lamport revisited some of the seminal works on distributed systems:
- The Mutual Exclusion Problem: E. W. Dijkstra. Solution of a problem in concurrent programming control. Communications of the ACM, 8(9):569, September 1965.
- Producer-Consumer Synchronization: identified as concurrency problem in: E.W Dijkstra, Cooperating Sequential Processes. EWD (1965). Dijkstra implicit model is based on the representation of a execution as a sequence of states, it is called the standard model.
- Proving Invariance Properties in the Standard Model. Edward Ashcroft, Proving Assertions in Parallel Models (1975).
Then, he did talk about a well known article:
 |
Finalizing with the Liveness & Fairness problem. And saying that the best way to reason formally about liveness was the article of Amir Pnueli, The Temporal Logic of Programs. FOCS (1977).
What happened in 1978?
R: Fault-Tolerance was introduced.
(Introduced by Dijkstra in 1974, but no one noticed)
Afternoon session’s speaker was Lorenzo Alvise, talking about consistency vs. performance. DISCLAIMER: I took less pictures because the light was not good, so I copy-pasted from the original articles in order to explain better the talk.
 |
Lorenzo started asking: what consistency means? and explained that there was (is) a semantic gap between Database people and for systems people. The key was to study about transaction’s serializability.
Then his talk was about explaining the following works:
A Critique of ANSI SQL Isolation Levels. Berenson et al, SIGMOD’95. ANSI isolation levels should be intended to proscribe phenomena, not anomalies. Thus, ANSI SQL phenomena are weaker than their locking counterparts.
Phenomenons are expressed to single object histories, but consistency often involve multiple objects. So, same guaranties are needed for running and committed transactions, but optimistic approach tire on the difference. The solution was Snapshot Isolation: a guarantee that all reads made in a transaction will see a consistent snapshot of the database (in practice it reads the last committed values that existed at the time it started), and the transaction itself will successfully commit only if no updates it has made conflict with any concurrent updates made since that snapshot.
Semantic gap between how isolation guarantees are defined and how are experienced by application programmers. Definition (in terms of histories and operations, invisible to applications) is not the same as Perception (Properties of observable states). This inspire more scalable implementations by not tying definitions down to system-specific assumptions. For instance:
A state-based definition Crooks et al, 2017: http://www.cs.cornell.edu/lorenzo/papers/Crooks17Seeing.pdf
Salt: Combining ACID and BASE in a Distributed Database: https://www.usenix.org/system/files/conference/osdi14/osdi14-paper-xie.pdf.
The committed state of an alkaline subtransaction is observable by other BASE or alkaline subtransactions. By leveraging this finer granularity of isolation, BASE transactions can achieve levels of performance and availability that elude ACID transactions.
Salt achieves most of the ease of programming of ACID and most of performance of BASE by rewriting performance-critical transactions incrementally. However, the extra programming effort involved is still non-trivial and can easily introduce bugs. Callas aims to move beyond the ACID/BASE dilemma. Rather than trying to draw performance from weakening the abstraction offered to the programmers, Callas unequivocally adopts the familiar abstraction offered by the ACID paradigm and set its sight on finding a more efficient way to implement that abstraction.
Callas then decouples the concerns of abstraction and implementation: it offers ACID guarantees uniformly to all transactions, but uses a novel technique, modular concurrency control (MCC), to customize the mechanism through which these guarantees are provided.
But Callas is not perfect:
 |
Solution? Transaction Chopping(Shasha et al. ’95) in the form of Runtime Pipelining (RP), a static and automatic analysis which produce the best slicing: slices that are serializable and also with the best performance. RP first statically constructs a directed graph of tables, with edges representing transactional data / control-flow dependencies, and topologically sorts each strongly connected set of tables. Transactions are correspondingly reordered and split into steps.
 |
Problem? Self conflict, the only way to avoid chopping conflicts is not chopping at all. Solution? TEBALDI hierarchical and modular CC.
End of day 1: hiking and then go watch the Atlantic Ocean.
 |
| "sunset" at 19:00 |
SATIS 2018 — Day 2
 |
0:20. I wanted a picture of northern lights, but I’ve only got this one… and a cold.
|
The talk started with some key points of replication history: going back to early seventies with the work of Mullery “The distributed control of multiple copies of data” (1971), Johnson & Thomas “Maintenance of duplicate databases” (RFC 677, 1975), Alsberg & Day “A principle for resilient sharing distributed resources” (1976), Lamport “Time, clocks, and the ordering of events in a distributed system” (1978), and Thomas “A solution to the concurrency control problem for multiple copy databases” (1978).
What is State Machine Replication?
A generic way to tolerate failures, the objective is to have a single copy behavior, simply starting multiple replicas(copies) of a deterministic state machine, and keep them in sync by agreeing on the inputs and the order in which to apply them. The model runs under a set of assumptions (“the more assumptions you make the worst it is, each assumption is a vulnerability”) about timing(no bounds on timing!, such as latency, speed, clock synchronization, etc.), node failure, and communications (loss, reordering and duplication allowed, fair links, perfect checksums). But replicas are expensive, so we have to think well what kind of fault tolerance we want.
 |
Van Renesse focused on Fail-Stop, because replicas are expensive and Fail-Stop is a reasonable assumption in datacenters, Asynchrony because latency bounds would have to be very conservative and results in slow systems, and FIFO communication because it simplifies life. Also, he did not considered disks because logically there is no significant difference between a processor with or without a disk.
Some existing replication protocols for the Fail-Stop Model are Primary-Backup(1976) and Chain Replication(Van Renesse & Schneider, 2004). Both assume an external configuration service that reconfigures surviving replicas after a failure. But, in practice, you don’t need such a service.
The system is based in two replicated systems: a head and a tail. Updates are directed from a proxy to the head, which propagated to the tail. Queries are directed from the proxy to the tail. When there is a failure, the remaining processor becomes both the head and the tail: if the head fails you only have to look to the tail replica (there is the state of the system, mostly nothing happens), and if the tail fails magically its history becomes instantly stable so it can handle the queries.
 |
| When a new process came to the system |
No external configuration service needed, state transfer is entirely in background, after state transfer, tail failure can be tolerated.
Generalizing to > 2 replicas, it is called chain of replicas, where each replica maintains a “speculative configuration” based on the configuration operations it has in its speculative history. A configuration command becomes stable when it reaches the tail.
 |
| Chain of replicas |
Following talk was Christian Cachin, with his talk:
 |
| Blockchain! [pretends to be shocked...] |
Cachin explained that a blockchain is a distributed system for executing and recording transactions, which is maintained by many nodes without a central authority. All nodes collaboratively validate the information to be included in the blockchain through cryptography and distributed consensus. Blockchains offer resilience and security based on the collective trust placed in the nodes maintaining it.
He revisited protocols for Byzantine consensus and explore older and newer protocols that power blockchains. He started from the very beginning: the Ledger. Ledgers record all business activity as transactions, every market and network defines a ledger, which records asset transfers between participant. Every market has its ledger and every organization has it own ledger.
 |
| Blockchain: Distributed Ledgers |
So, the question is, do you need a blockchain? (NdR: no), four necessary features of a distributed blockchain task are: it stores data, multiple nodes write, not all writing nodes are trusted, and operations are (somewhat) verifiable. If any feature is missing don’t use blockchain.
One of the best things of blockchain is transactions can be arbitrary code (smart contracts), embody logic that responds to events (on blockchain) and may transfer assets in response. How consistency is ensured? giving the probabilistic approach, forks occurs regularly but do not last forever (with high probability). Probability of k-blocks long fork is exponentially small in k
When constructing a block the node has to validate all Tx and decides an ordering within block. Then, it must assure that only valid transactions enter the blockchain, that is, re-run all the smart-contract code. Validation can be expensive, for instance, bitcoin blockchain contains the log of al Tx ~180GB as of 8/2018
Further information at “Distributing Trust on the Internet”, Christian Cachin, in Proc. Intl. Conference on Dependable Systems and Networks (DSN-2001), Gothenborg, Sweden, IEEE, 2001.
“In cryptography it is impossible to demonstrate that a cryptosystem works because one can only demonstrate that it fails, we must treat consensus like cryptosystems”.
The talk also introduces Hyperledger Fabric, a modular and extensible blockchain platform that is developed open-source under the Hyperledger Project and which was originally contributed by IBM. Fabric introduces a novel architecture for building resilient distributed systems that differs from the conventional paradigm, in order to accommodate flexible trust models, to cope with non-determinism, and to prevent resource exhaustion. There are currently several hundred prototypes, proofs-of-concept, and production systems of distributed ledger technology that use Fabric as a platform for distributing trust over the Internet.
Final lecture of the day was Michael Franklin with: “Distributed Data Analytics”.
 |
“The relational model provides a basis for a high level data language which will yield maximal independence between programs on the one hand and machine representation on the other” (E.F: Codd, CACM 1970, emphasis added by Michael)
But, how to get good performance?
Shortly after the relational model was introduced, several companies sells “relational database management systems”, machines “capable to run relational queries” with domain specific hardware. But the academia disagreed:
“We claim that “of-the-shelf” processing components provide sufficient processing power and that there is no need to implement customized database processor either through microcode or VLSI...” (Boral & DeWitt International Workshop on Database Machines, Munich 1983)
Also, it was interesting to study “The case for shared nothing”by Stonebraker, comparing three architectures for BD machines: shared memory, shared disk, and shared nothing. (High Performance Transaction Processing Workshop, Asilomar 1985). The paper argued that shared nothing was better. This kind of design scaled very well until around 2010 thanks to declarative, set-oriented language (SQL) and Moore’s Law.
Shared-Nothing Queries basics: types of parallelisms can be inter-query and intra-query (inter-operator such as tree and pipeline and intra-operator such as divide & conquer). Data partitioning By range? By hash? Round robin? (why is good round robin? You will be always bounded by your slower processor), scans in Parallel? Because each system is a full-blown DBMS indexes can be built at each partition and partial query plans can be executed at each node. Sorting? Is more challenging, so you make a local sort and then a merge them, or having partitioned data the sort is made after receive the data. In the latter, one can sample to estimate data distribution and choose ranges to get uniformity. Joins? The good case is without data movement (all tables well organized & partitioned parallelism), but…
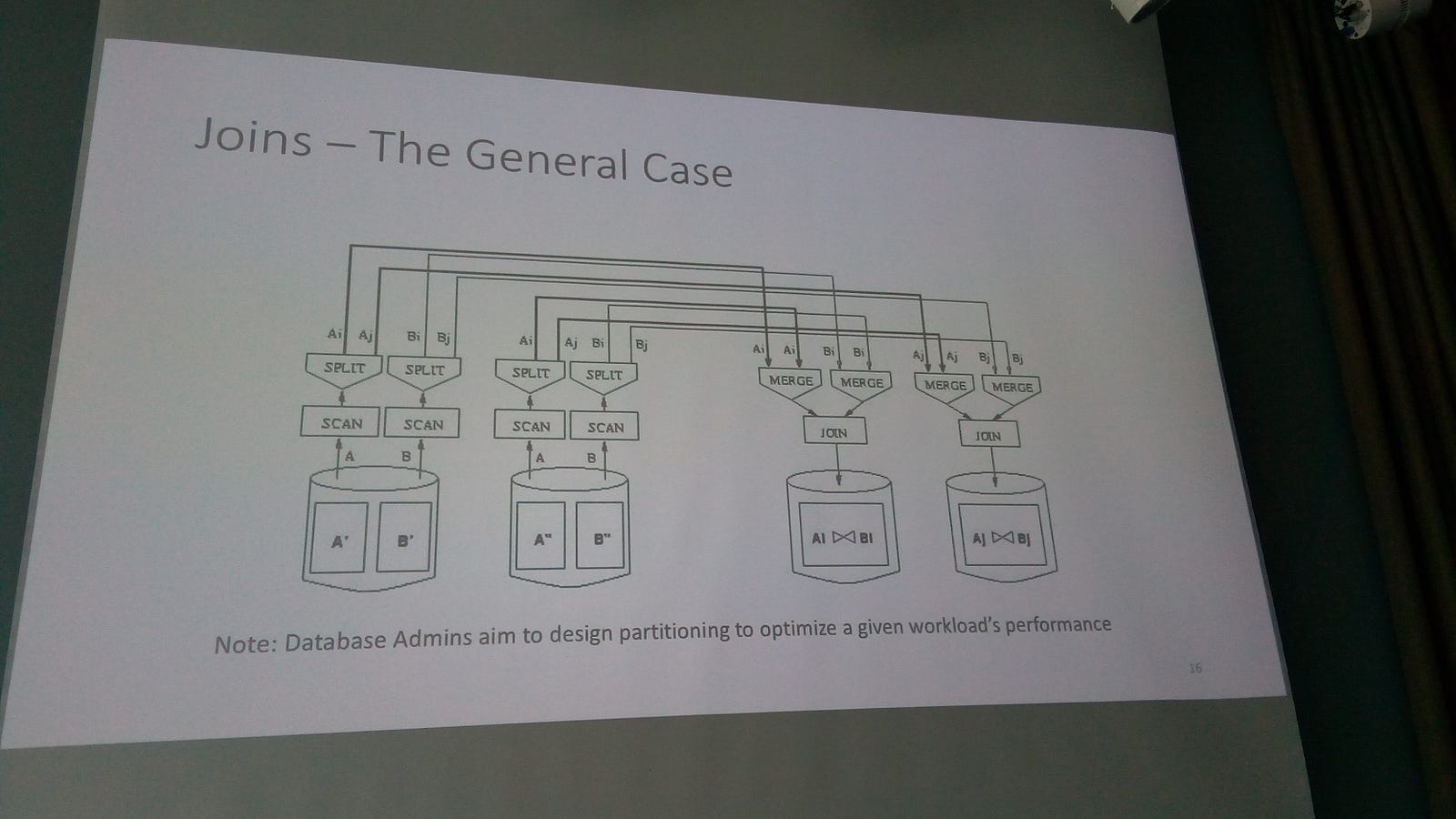 |
| a "basic" join |
Grouping? Again, skew is an issue, approaches: avoid (choose partition function carefully) or react (migrate groups to balance load)
Map-reduce?
 |
| map-reduce |
That was all the last 30+ years. Shared-nothing on commodity servers has been “gold standard” But… a massive shift is coming: Data analytics moving to the cloud, closed and open source “big data” platforms (hadoop, spark, impala, etc), cloud architectures are becoming disaggregated, end of Moore’s law and rise of machine learning.
Why people is moving to the clouds?, mostly because their rock bottom storage prices and high elasticity. Also, initial security concerns were addressed (and largely unfounded).
This is, the rise of shared storage.
Then, Michael compared 3 examples of this “new” design, using the slides of “The End of Shared Nothing” by David J. DeWitt because, on his words, “it was better explained there” (PPTX slides available here, and in fact, the systems are veeery well explained on David’s slides :-))
- Amazon (AWS) Redshift (single leader node, one or more compute nodes — EC2 instance, one slice/core per database, memory, storage & data partitioned per slice), hash & round robin data partitioning, unique fault tolerant approach (each 1MB blocks get replicated on another node and on a S3)
- Snowflake Elastic DW: compute decoupled from storage, highly elastic. Query-level control through Virtual Warehouse mechanism
- SQL DW: DB-level adjustment of DWU capacity
Rise of Machine Learning: ML increasingly part of the Data Analytic pipeline, increasingly, application require multiple modes of analytics: query, graph, streaming, machine learning, deep learning.
Michael Franklin finished his Lecture with the following message:
IoT and Edge processing, for latency, reliability, privacy, legal and actuation reasons, some analytics will need to be processed at the edge of the network, this is an extreme version of “shared nothing”. There’s a desperate need for innovation and lots of great research to be done.
Poster Session
There were no many posters as students on this school, but the few the better :-) and most of them were very interesting. I post my two favorites:


Lukas Burkhalter presented his work using a very nice mathematical trick for creating a set of keys where the K(i+1) key depends on K(i) for its calculation. The whole system is intended to protect the users privacy on crowd data storages.
Nikos Kouvelas presented his work about a new LoRaWAN-MAC protocol which guarantees maximum channel throughput, one of the few network-related works at the school, it is interesting because actually LoRaWAN throughput has been reported less than 50 kbps in optimal conditions, and its MAC protocol seems to be one of its bigger bottlenecks.
 |
Final activity of the day, the dinner.
|
SATIS 2018 — Day 3
It is a rainy day here in Sommarøy. Talks started at 9:30, but some of the students leave to the airport at 4:30.
First talk was from Fred Schneider, “Security from Tags”, a joint work with Elisavet Kozyri.
 |
| Fred Schneider |
Reference monitors typically enforce security policies by intercepting operation invocations — the policy to be enforced is decomposed into operation-specific checks. Fred’s lecture discuss a data-centric alternative. Here, labels are attached to data, and each label gives a policy that describes how the associated value may be used.
Mediate operation invocations: Employ a reference monitor for operations, checks typically performed at runtime by OS, handles all “safety properties”.
Mediate uses of values: associate tags with values, often implemented by type-checking handling some “hyper-safety properties”. But, a property like confidentiality can’t be checked looking only an execution. Confidentiality is not a safety property.
Mediate uses of values:
- Confidentiality: Restrict which principals allowed to “learn” information about v
- Integrity: Restrict which pincipals must be trusted in order for vto be trusted
- Privacy: Restrict allowed uses of v.
Enforcement: Access Control. Identity of requests is basis for restricting access, there is access control on containers (requires understanding system internals) and on contents (requiring policy independence from internals and can provide “end to end” guarantees).
To support access control on contents he used tags and values: a tag Tv is associated with every value v and variable v, it specifies allowed uses of v and implementing enforces restrictions in tags. What will happen with the restriction for derived values? the restrictions could depend on the restriction of variables, the semantic of the operation and/or the values of the variables. So, we need a way to introduce the tags into derived values for a function F used to combine values.
 |
| [Tx]F.i is the tag of variable X when it is passed as i-th parameter to F |
There is also a restrictiveness relation for tags (squared ≤), defining that a value yis allowed to influence values in x. This is very interesting for instance to study newspaper biases. Tags form a join semi-lattice.
 |
| composing restictions |
Flow derived restrictions: Restrictions associated with a value vare determined only from restrictions associated with values v’that influenced v. Lattice of tags specifies when “influence” is allowed.
The idea, then, is to associate tags with restrictions enforcing flow-derived restriction policies on program. Using type-checking or dynamic enforcement if the join is computable and sound (no false positives) if not complete (false negatives possible) decision procedure for the restrictiveness. That will produce a “checkable” class of tags. A new class of reactive information flow (RIF) labels is needed to fully support this view.
 |
| RIF tags |
Values and variables are tagged with labels and subject to restrictions R(p) [v]F has tag T(p,F) and it is subject to restrictions R(T(p,F)). So now the restrictiveness can be defined in terms of R.
Schneider discussed the design of these RIF labels and describe a static enforcement scheme, giving examples of their use and presenting JRIF (from JIF, a RIF extension for Java, further information here). He also discussed the need for label chains when run-time enforcement is employed giving some foundational results to characterize trade-offs.
 |
| Label Chains |
 |
| Group Photo Pause |
Last (but not least) talk of the School was Idit Keidarwith “Distributed Storage Fundamentals”.
 |
| "Do you know really where is your data?" |
With the increase in storage capacity demands, scalable storage solutions are increasingly adopting distributed storage solutions, where storage nodes communicate over a network.
 |
| "If you talk about systems, you have to talk about failures. Can we provide the illusion of reliable atomic shared-memory in a message-passing system? in an asynchronous system? where clients and server can fail?" |
This talk discussed the principles of building fault-tolerant distributed storage. For instance, in a Failure-Freecase we can implement state machine replication with atomic broadcast to propagate updates. But, if a process can crash this solution doesn’t work anymore.
So, let’s start with a simple Single Reader SingleWriter. We will have to move to a sort of ABD [Attiy, Bar-Noy, Dolev 95] algorithm for emulating reliable shared storage using fail-prone storage nodes and the quorum-replication approach.
ABD assumes up to f < n/2 processes can fail, it stores value at majority of processes before write completes and reads from majority. Read intersects write, hence sees latest value. What is the linearization order when there is overlap between read and write? What if 2 reads overlap?.
When reader receives (“read-ack”, v, tag) from majority it choose value v associated with largest tag, store the values in x,t send (“propagate”,x,t)to all (except write). Upon receive (“propagate”, v, tag) from process i it will update its copy if newer, and send back an ack to i.
But, what if two writes use the same tag for writing different values? Need to ensure unique tags. What if a later write uses a smaller tag than an earlier one? We need to perform a “read before write” (2 phase write).
Can we solve shared memory consensus in a general way? No
 |
It is all based on the Ω leader election, the leader only fails if there are contention. In shared memory systems, Ω is called contention manager. Leader always proposes its own value or one previously proposed as earlier value.
 |
Optimization: the first write (of b) does not write consensus values, a leader running multiple consensus instances can perform the first write once and for all and then perform only the second write for each consensus instance.
 |
Idit Keidar presented atomic transactions over shared storage using a combination of ABD and SM paxos. Then she followed with some open problems and challenges:
 |
| What to do? |
See: “Dynamic Reconfiguration: Abstraction and Optimal Asynchronous Solution”. Alexander Spiegelman, Idit Keidar and Dahlia Malkhi, DISC 2017.
And space bounds on distributed storage:
 |
| Slicing the DB |
What happend when there is concurrency? See: Spiegelman et al. at PODC 2016, and Berger et al. at DISC 2018.
Final remarks: I would like to thank the organization of SATIS 2018, everything was perfect and I will be glad to go to the second school (if it takes less than 20 hours of flight).